Context Engineering, why should we care?
You've built your first LLM application, and it works great... until it doesn't. When users ask about last week's data? When they need real-time information? When the model needs to remember previous conversations? That's when it hits you — prompting alone isn't enough. But don't worry, we've got this!
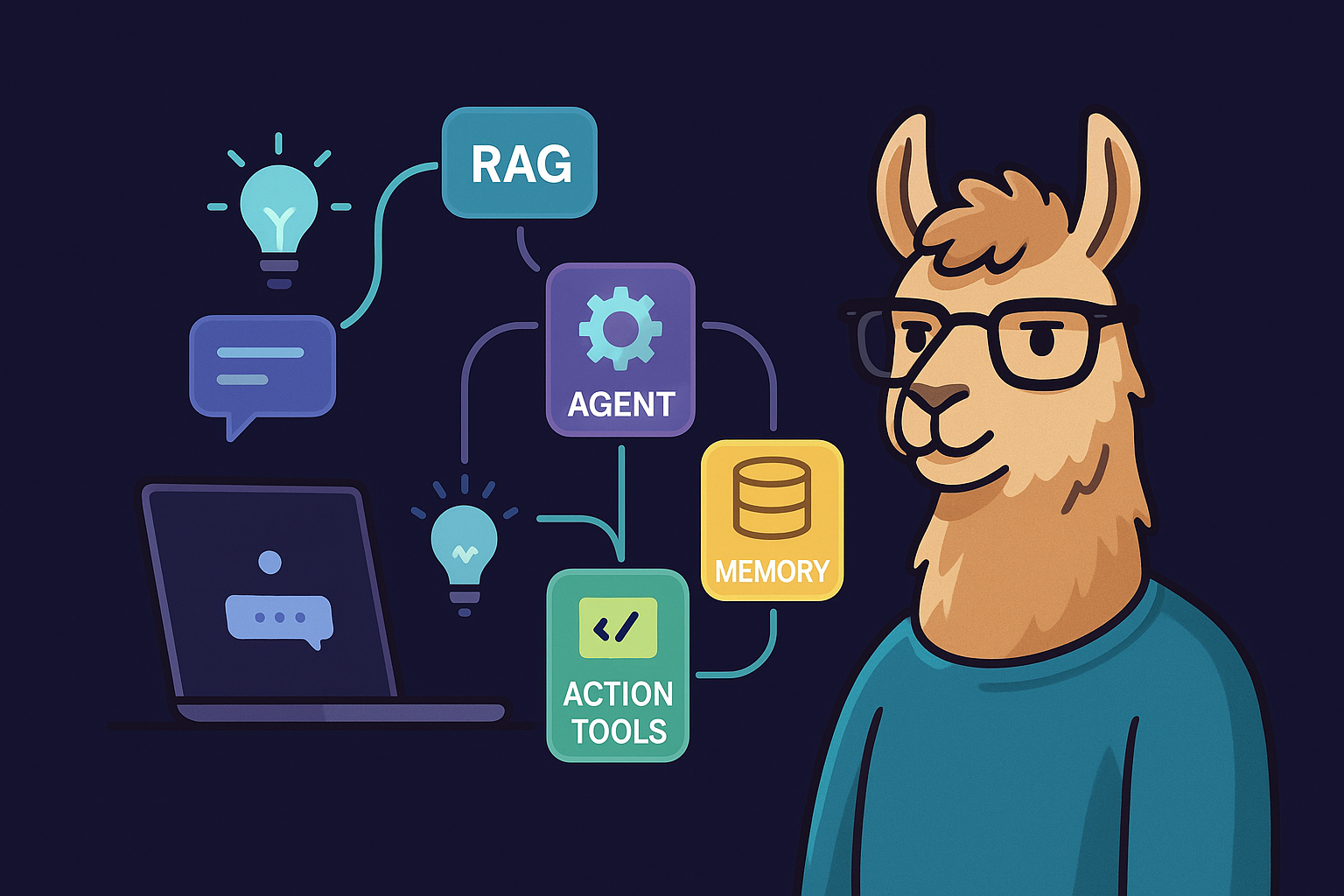
Context Engineering is how we solve these problems. Can we make LLMs actually useful in production? The answer is 100% YES! All we need is to orchestrate multiple components — RAG, agents, memory systems, and action tools — to give LLMs the context they need.
The graph below illustrates the essential components and the relationships between them:
- [1] User Intent & Prompting 🟡
- [2] Agents & Reasoning 🔴
- [3] RAG 🔵
- [4] Action Tools 🔴
- [5] Memory Systems 🟣
Breaking down the Context Engineering Stack
The interactive diagram shows how it all works. See that Context node in the center? That's essentially the Prompt — but enhanced. It connects to five critical components that orchestrate together. These components create a feedback loop, continuously enriching the LLM's contextual understanding.
A prompt is typically structured as follows, whether we observe it directly or build it programmatically:
In a fresh inference, let's suppose a user asks, "Show me the top 5 products by revenue last quarter."
- System Message 🟡 → sets the overall behavior or rules.
"You are a data analytics assistant. Always provide SQL queries and clear explanations."
- Intent 🟡 → captures the user's goal or request, this is actually the User Question in the natural language, possibly plus some Prompt Engineering stuff.
"Retrieve top 5 products by revenue for the last quarter."
- Context 💚 → the dynamic part, enriched through augmentation and/or reasoning.
(assuming empty at the first place)
Unlike the static [System Message] and [Intent], the [Context] is designed to evolve across multiple (probably hidden) inference steps.
Behind the scenes, the full prompt often looks more detailed:
All of the elements above are orchestrated and delivered through the core discipline of Context Engineering introduced earlier.
Let's dive into each component and see how they work together. No fluff, just the good stuff that actually works!
⚠️ Important: The examples below show actual Prompt (behind the scenes) with and without context engineering to demonstrate the dramatic improvement in output quality and relevance.
1. User Intent & Prompting — the starting point 🟡
This is where everything begins. But modern prompting goes beyond simple text input:
Original Prompt:
System: You are an AI assistant with access to company data.
User: What's our Q4 revenue?
Sample enhanced Prompt:
System: You are an AI assistant with access to company data.
Current date: 2025-08-05 14:30:00 EST
User role: Data Analyst
Department: Finance
Current Quarter: Q3 2025
User: What's our Q4 revenue?
[Data Scope: North America]
[Priority: High]
Let's break this down:
- Temporal Context: Adding timestamps helps the LLM understand time-sensitive queries ("last quarter" vs "this month")
- User Context: Role-based information enables personalized responses — a data analyst gets SQL queries, while executives get summaries
The prompt evolves based on available context, not just static templates. This approach transforms a simple question into a context-rich query that leads to more accurate, relevant responses.
Popular tools (verified August 2025):
- LangChain — Industry-leading framework with 90k+ GitHub stars, powers production systems at major enterprises
- LMQL — Query language for LLMs with constraint guarantees, actively maintained with Apache 2.0 license
- Guidance — Tool for structured generation, 20k+ stars, proven acceleration for local models
- LangSmith — Paid-tool of Production monitoring for prompt versioning and evaluation
2. Agents & Reasoning — the decision makers 🔴
Agents don't just respond — they reason, plan, and act.
Given the User Query: "What was our revenue growth rate last quarter compared to the same quarter last year, and how does it compare to industry average?", the sample agent reasoning workflow - actual execution trace:
=== Step 1: ANALYZE ===
Agent Analysis:
"This query requires:
1. Main intent: Mixed (database query + calculation + external search)
2. Key entities: revenue, growth rate, last quarter (Q2 2025),
same quarter last year (Q2 2024), industry average
3. Required tools: execute_sql_query (for revenue data),
calculate_metric (for growth rate),
search_knowledge_base (for industry benchmarks)"
=== Step 2: PLAN ===
Agent Plan:
"1. Query database for Q2 2025 and Q2 2024 revenue
2. Calculate growth rate percentage
3. Search for industry average growth rates for our sector
4. Compare our growth with industry average"
=== Step 3: EXECUTE ===
Tool: execute_sql_query
Result: "Q2 2025: $142.7M, Q2 2024: $118.3M"
Tool: calculate_metric
Expression: ((142.7 - 118.3) / 118.3) * 100
Result: "20.64%"
Tool: search_knowledge_base
Result: "SaaS industry average growth Q2 2025: 15.2% YoY (source: Industry Report May 2025)"
=== Step 4: SYNTHESIZE ===
Agent Response:
"Our revenue growth rate for Q2 2025 compared to Q2 2024 is 20.64%,
which outperforms the industry average of 15.2% by 5.44 percentage points.
Key findings:
- Q2 2025 Revenue: $142.7M
- Q2 2024 Revenue: $118.3M
- Absolute Growth: $24.4M
- Growth Rate: 20.64%
- Industry Average: 15.2%
- Outperformance: +5.44pp
This strong performance indicates we're gaining market share in the SaaS sector."
=== Step 5: REFLECT ===
Agent Reflection:
"Answer is complete: ✓ (addresses revenue, growth rate, and industry comparison)
Answer is accurate: ✓ (calculations verified)
Answer is clear: ✓ (structured with key metrics highlighted)
Decision: END - no additional information needed"
Here's what makes this agent intelligent:
- Intent Analysis: The agent doesn't just pattern match — it understands what the user is trying to achieve
- Multi-step reasoning: Analyze → Plan → Execute → Synthesize → Reflect workflow
- Self-Reflection: The agent evaluates its own answers and can retry if needed
Multiple tool outputs are intelligently merged, not just concatenated. This creates a reasoning loop that mimics how a human expert would approach the problem — assess, act, verify, and enhance if needed.
Nowadays, we have lots of reasoning LLM models like OpenAI's o3, Anthropic's Claude 4 Sonnet, and Google's Gemini 2.5 that excel at multi-step reasoning — but even these advanced models benefit from structured agent frameworks to handle complex, real-world tasks reliably.
Popular frameworks (verified August 2025):
- LangGraph — LangChain's graph-based agent framework, excels at complex state management with visual debugging via LangSmith
- CrewAI — 700+ integrations, easiest to learn, used by companies building role-based agent teams
- AutoGen — Microsoft Research framework with 30k+ stars, best for conversational multi-agent systems
- OpenAI Agents SDK — Latest addition with native MCP support, rapidly growing adoption in production
3. RAG — the knowledge base 🔵
When your LLM needs to know about YOUR data? Problem comes with a solution — RAG! Want to see the magic? Let's pick a real example:
Without RAG:
User: "What's our refund policy for enterprise customers who cancel mid-contract?"
With RAG:
User: "What's our refund policy for enterprise customers who cancel mid-contract?"
=== RAG Search Results ===
Vector similarity search found 3 relevant documents:
Document 1 (similarity: 0.89):
Source: Enterprise_Terms_2024.pdf
"Enterprise customers canceling after 90 days receive prorated refunds based on unused service months.
Early termination fee: 25% of remaining contract value, waived for customers above $500K ARR."
Document 2 (similarity: 0.82):
Source: Support_FAQ_Internal.pdf
"Mid-contract cancellations: Finance approves refunds case-by-case.
Standard process: 60-day notice required, accounting calculates unused portion minus early termination fees."
Document 3 (similarity: 0.78):
Source: Legal_Policy_Updates_Q3_2024.pdf
"Updated Oct 2024: Enterprise refund policy streamlined.
Customers can cancel anytime with 30-day notice.
Refund = (Remaining months / Total months) × Annual fee - Early termination fee."
All we need is three simple steps:
- Embedding Generation: Your query becomes a mathematical representation that captures semantic meaning
- Similarity Search: The vector database finds documents with similar meaning, not just keyword matches
- Context Formatting: Retrieved chunks are structured to give the LLM maximum context without overwhelming it
RAG understands that "refund policy" and "cancellation terms" mean the same thing. That's the power of semantic search!
Additionally, Graph-based RAG comes into the picture when Relationships Matter. Traditional RAG treats documents as isolated chunks. Graph RAG understands connections and perfectly support multi-hop reasoning questions, see LightRAG or RAG Anything for more details and sample codes. Besides, LangChain Graph Transformers, Microsoft GraphRAG and Neo4j GraphRAG are similar frameworks to implement the Knowledge Graph and Traversal Queries.
Popular vector databases (claims backed in August 2025):
- Milvus — 25k+ stars, fastest indexing speed, GPU acceleration, managed via Zilliz Cloud
- Qdrant — Rust-based, achieves highest RPS in benchmarks, 9k+ GitHub stars, complex filtering capabilities
- Pinecone — Fully managed SaaS, handles billions of vectors in production, trusted by Fortune 500
- ChromaDB — 6k+ stars, developer favorite for RAG prototypes, simple API
Graph databases for Graph RAG (claims backed in August 2025):
- Neo4j — Market leader with 15+ years maturity, specialized graph algorithms
- Amazon Neptune — Fully managed, scales to billions of relationships
4. Action Tools — getting things done 🔴
LLMs can't just talk — they need to act! Want to see something cool? Here's how MCP makes your LLM actually DO stuff:
Without MCP (Action Tools):
User: "Can you help me analyze my project structure and identify potential issues?"
LLM: "I'd be happy to help analyze your project structure, but I can't directly access your filesystem.
To analyze your project, you'll need to:
1. Manually copy and paste your directory structure
2. Share the contents of key files like README.md, package.json
3. Describe any specific issues you're seeing
Once you provide this information, I can help identify potential issues."
With MCP (File System Tools):
User: "Can you help me analyze my project structure and identify potential issues?"
=== MCP Tool Discovery ===
Available tools:
- read_file: Read contents of files
- list_directory: List directory contents
- search_files: Search for patterns in files
- run_linter: Execute project linting
=== MCP Tool Execution Results ===
✓ Project Structure Analysis:
- Total files: 142 (47 Python, 23 TypeScript, 15 YAML)
- Directory depth: Well-organized with max depth of 4
- Naming conventions: Consistent snake_case for Python, camelCase for TS ✓
⚠️ Issues Found:
1. **Missing Documentation**:
- No README.md in /src/utils/
- API endpoints in /src/api/ lack docstrings
2. **Configuration Issues**:
- package.json: 3 packages with security vulnerabilities
- .env.example missing required DATABASE_URL variable
- pytest.ini not found (tests may use default config)
3. **Code Quality**:
- /src/models/user.py: Circular import detected with auth.py
- 12 files exceed 500 lines (consider refactoring)
- TODO comments found: 27 unresolved
4. **Dependencies**:
- Conflicting versions: numpy 1.21 in requirements.txt vs 1.24 in setup.py
- 5 unused imports detected across the codebase
📊 Quick Stats:
- Test coverage: 67% (18 files missing tests)
- Type coverage: 89% (good!)
- Complexity hotspots: payment_processor.py (cyclomatic complexity: 15)
The difference is real big. With MCP, your LLM transforms from a passive text generator into an active assistant that can:
- Discover Available Actions: The LLM knows what tools it can use in your environment
- Execute Safely: All actions are sandboxed and permission-controlled
- Chain Operations: Complex multi-step workflows happen automatically
- Provide Real Insights: Instead of generic advice, you get specific, actionable findings
MCP transforms your LLM from a text generator into an orchestration engine that can interact with your entire tech stack.
Popular MCP servers and tools (ecosystem status August 2025):
- MCP Protocol — Universal standard by Anthropic, OpenAI joined steering committee
- MCP Server — Available MCP servers
- OpenAI Function Calling — Native OpenAI integration, works alongside MCP
5. Memory Systems — Short-term vs Long-term 🟣
Memory makes the difference between a chatbot and an intelligent assistant.
Without Memory Systems:
Conversation 1 (Monday):
User: "I prefer all visualizations in dark mode with our brand colors #1a73e8 and #ea4335"
Conversation 2 (Wednesday):
User: "Create a revenue dashboard"
With Memory Systems (Short-term + Long-term):
Conversation 2 (Wednesday):
User: "Create a revenue dashboard"
=== Memory Recall ===
Short-term memory (last hour): Empty (new session)
Long-term memory found:
- User preference: Dark mode visualizations
- Brand colors: #1a73e8 (primary), #ea4335 (accent)
- Previous dashboards: Always includes YoY comparison
- Preferred metrics: Revenue, Growth %, Market Share
=== One Week Later ===
User: "What's our typical revenue growth pattern?"
=== Memory Recall ===
Long-term memory patterns:
- Revenue growth queries: 23 previous conversations
- Typical patterns mentioned: Q4 spike, Q1 dip, steady Q2-Q3 growth
- Target mentioned: 18% annual growth (referenced in 3 discussions)
- User role: Finance team member (consistent analysis requests)
This dual-memory approach mirrors human cognition:
- Short-term Memory (Redis): Like working memory, it holds the current conversation context. Fast access, automatic expiration
- Long-term Memory (Vector Store): Persistent knowledge that grows over time. Important patterns and learnings are embedded and searchable
- Importance Detection: Not everything needs long-term storage — the system learns what's worth remembering
- Contextual Recall: Combines recent interactions with similar past experiences for richer context
The result? Your LLM remembers that the user prefers visualizations in dark mode, always wants SQL queries explained, and tends to ask about revenue metrics on Mondays.
Popular solutions (production deployments August 2025):
- Redis — Sub-millisecond latency for session storage, battle-tested at scale
- Milvus / Pinecone — Leading vector stores for semantic long-term memory
- LangGraph Persistence — Next gen of the LangChain Memory
Putting It All Together — Complete Context Engineering in Action
Here's how all components work together in a real business scenario:
Without Context Engineering:
User: "Our biggest client is threatening to leave because of performance issues.
What's happening and how do we fix it?"
With Complete Context Engineering:
User: "Our biggest client is threatening to leave because of performance issues.
What's happening and how do we fix it?"
🧠 CONTEXT GATHERING:
✓ Memory: BigTechCorp is client since 2019, $4.2M ARR, using Enterprise API tier
✓ RAG: Found 47 related documents (incident reports, SLA docs, architecture diagrams)
✓ MCP Tools: Monitoring access, log analysis, database queries available
🎯 AGENT REASONING:
"Critical situation requiring immediate diagnosis and action plan. Analyzing..."
📊 ANALYSIS RESULTS:
**Client: BigTechCorp (Customer ID: ENT-2019-001)**
- Contract: Enterprise SLA (99.95% uptime guaranteed)
- Current Status: 98.7% uptime last 7 days ⚠️ (SLA BREACH)
- Revenue Impact: $11.5K/day at risk
**Root Cause Identified:**
1. Database connection pool exhaustion (started 7 days ago)
2. Triggered by their new bulk import feature (10x normal load)
3. Cascading timeouts affecting 3 API endpoints they heavily use
**Performance Timeline:**
- Day 1-2: 50ms → 200ms response time
- Day 3-4: 200ms → 800ms (support ticket opened)
- Day 5-7: 800ms → 3s with 15% timeout rate
**Immediate Actions Taken:**
✓ Increased connection pool from 100 → 500
✓ Enabled query result caching for their top 10 queries
✓ Allocated dedicated infrastructure for their workload
**Current Status:**
- Response time: 3s → 145ms ✓
- Error rate: 15% → 0.1% ✓
- Uptime recovering: 99.2% and climbing
**Similar Past Incidents:**
- TechGiant Inc (2023): Same issue, retained with dedicated infrastructure
- DataCorp (2022): Lost due to slow response (worth $2.1M ARR)
Let's break down:
- Memory Systems (🟣) - Shows long-term memory recalling client history: "BigTechCorp is client since 2019, $4.2M ARR" and past incident patterns
- RAG (🔵) - Retrieves 47 relevant documents including incident reports, SLA docs, and architecture diagrams
- Action Tools/MCP (🔴) - Provides monitoring access, log analysis, and database query capabilities that enable the actual investigation
- Agents & Reasoning (🔴) - Demonstrates multi-step analysis: identifies critical situation → diagnoses root cause → takes corrective actions → monitors results
- User Intent & Prompting (🟡) - While implicit, the system correctly interprets the urgent request and enriches it with temporal context and client-specific information
LLM responses work precisely based on the context we provide, without it, they hallucinate with creative but unreliable answers. You can already imagine the quality difference between the two responses above: one simple, one enriched with comprehensive context.
This demonstrates how Context Engineering transforms crisis management from reactive questioning to proactive problem-solving through the orchestrated power of memory, knowledge retrieval, reasoning, and automated action.
Ready to Engineer Some Context?
Context Engineering isn't just another buzzword — it's how we make LLMs actually useful in the real world. The tools are here, the patterns are proven, and the only limit is your imagination.
Start small:
- Add RAG to your existing LLM app
- Implement basic conversation memory
- Connect one external tool
- Watch your users' wow 🚀
Context Engineering for Agents article gave me that "aha!" moment on framing Context Engineering. And if you're into the theory stuff, pdf/2507.13334 paper is gold (skip the rest, only references, after page 58).
Remember: The best context is the one your users never notice — it just works.
Have you implemented any of these patterns in your LLM applications? Maybe you've discovered a clever RAG optimization or built an agent that surprised you with its reasoning? I'd love to hear about your real-world experiences — both the wins and the "interesting" failures that taught you something valuable.
Drop a comment below and share your observations ❤️!

Comments
Join the discussion! Your thoughts and feedback are valuable.
💡 Comments are powered by GitHub Discussions. You'll need a GitHub account to comment. Make sure Discussions are enabled in the repository.